- 본 글은 MS COCO 키 포인트 평가 metric을 설명한 페이지인 https://cocodataset.org/#keypoints-eval를 번역하여 정리한 것입니다.
지금부터 COCO에서 사용하는 키포인트 평가 metric에 대해 알아보겠습니다.
아래에 제공하는 평가 코드를 사용하여 공개된 MS COCO validation 데이터 셋에 사용할 수 있습니다.
https://github.com/cocodataset/cocoapi
Python 코드의 cocoeval.py와 Python 코드(데모)에서 pycocoevalDemo.ipynb를 참조하여 평가 코드를 실행하기 전에 결과 format 페이지에 설명된 형식으로 결과를 준비하면 됩니다.
만약 COCO test 데이터 셋에 대한 결과를 얻고자 하는 경우, 생성된 결과를 평가 서버에 업로드해서 성능을 검증하시면 됩니다.
우선, 평가의 주된 내용에 대해 살펴보겠습니다.
평가 개요
COCO 키포인트는 Object Detection과 Keypoint localization을 함께 수행해야 합니다. 그렇기 때문에 Object Detection Metric에서 영감을 얻은 새로운 metric을 채택하였다고 합니다.
수행해야 하는 작업을 지금부터 키 포인트 검출(Keypoint Detection)로 키 포인트를 예측하는 알고리즘을 키 포인트 검출기(Keypoint Detector)라고 합니다.
이후 내용을 살펴보기 전에 Object Detection에 대한 평가 metric 설명 블로그 글을 먼저 보시기를 권장합니다.
키 포인트 검출 평가의 핵심 아이디어는 Object Detection에 사용되는 평가 metric인 Average Precision과 Average Recall을 변형하여 이용하는 것입니다. 이 metric에서 중요한 점은 Ground Truth 객체와 예측된 객체 사이의 유사성을 측정한다는 것입니다.
Object Detection에서는 IoU가 유사성을 측정하는 역할을 했고, IoU의 임곗값(threshold value)을 기준으로 Ground Truth 객체와 예측된 객체 사이의 매칭 여부를 판단하고 Precision-Recall Curve를 계산할 수 있었습니다.
Keypoint Detection에서 Precision과 Recall을 구하기 위해서는 유사성 측정 방법이 필요한데 여기에서 Object Detection의 IoU 역할을 하는 것이 OKS(Object Keypoint Similiarity)입니다.
그럼 지금부터 OKS에 대해 알아보도록 하겠습니다.
Object Keypoint Similarity
각각의 객체에 대해 Ground Truth 키 포인트는 $[x_1,y_1,v_1,...,x_k,y_k,v_k]$ 의 형식으로 되어 있습니다.
여기서 $x,y$ 는 키 포인트의 2차원 평면상의 위치이고, $v=0$ 이면 레이블링되지 않음(not labeled), $v=1$ 이면 레이블링 되어있지만 보이지 않음(labeled but not visible), $v=2$ 이면 레이블링되어 있고 볼 수 있음(labeled and visible) 으로 visibility flag가 됩니다.
추가적으로 Ground Truth 객체는 scale을 갖고 있는데 이 scale은 객체의 세그먼트 영역의 제곱근으로 정의한 값입니다.
COCO challenge의 목표는 각 객체에 대한 키 포인트 위치 $x,y$ 와 객체의 신뢰도(confidence)를 키 포인트 검출기를 통해 얻는 것입니다. 최종적으로 $x_1,y_1,v_1,...,x_k,y_k,v_k$ 의 결과가 필요하지만 평가 중에는 $v$ 는 사용되지 않으므로 가시성(visible or not visible)이나 혼동(labeled not visible)을 예측할 필요는 없습니다.
키 포인트의 유사성 측정 방법인 Object Keypoint Similarity(OKS)는 다음과 같이 정의됩니다.
$$OKS = \sum_{i}[exp(\frac{-d_i^2}{2s^2k_i^2})\delta(v_i>0)/\sum_i[\delta(v_i>0)] $$
수식의 구성 요소를 하나씩 살펴보겠습니다.
$d_i$ : Ground Truth 키 포인트와 검출된 키 포인트 사이의 Euclidean distance
$v_i$ : Ground Truth의 visibility flag (검출기의 예측된 $v_i$ 는 사용되지 않습니다)
$s$ : 객체 세그먼트 영역의 제곱근
$k_i$ : falloff를 제어하는 키 포인트마다 존재하는 상수
이 값은 표준 편차인 $sk_i$ 와 함께 정규화되지 않은 가우시안 함수에 $d_i$ 를 통과시킨 값을 의미합니다. 각 키 포인트에 대해 0과 1사이의 키 포인트 유사성을 계산한 값이 됩니다. 이 값들을 레이블이 있는 모든 키 포인트($v_i > 0$)에 대해 평균을 구합니다.
레이블링이 되어 있지 않은 예측 키 포인트는 OKS에 영향을 미치지 않습니다.
예를 들어, 왼쪽 손목을 키 포인트 검출기가 예측한 상황이고 왼쪽 손목이 레이블링 되어 있지 않은 경우 왼쪽 손목의 유사성(OKS)은 계산되지 않고 결과에 영향을 미치지 않습니다.
완벽한 예측인 경우 OKS 값은 1이 되고, 반대로 표준편차 $sk_i$ 에 대해 Ground Truth 키 포인트와 검출된 키 포인트 사이의 Euclidean distance의 정규화 되지 않은 가우시안 함수 값이 0이 될경우 OKS값은 0이 됩니다. 즉, Ground Truth와 검출된 키 포인트 사이의 Euclidean distance가 작을수록 OKS 값은 1에 가까워질 것입니다.
정규화 되지 않은 가우시안 함수를 이용하는 이유는 중심 값이 1이 되길 원하기 때문입니다.
다시 한 번 살펴보면, Ground Truth 객체와 예측된 객체사이의 유사성을 측정할 수 있다는 점에서 OKS는 IoU와 유사합니다. IoU로 AP와 AR를 구한 것처럼 OKS가 주어진 상황에서도 AP와 AR을 계산할 수 있습니다.
이제까지 OKS를 구하는 방법에 대해 알아보았습니다.
그럼 지금부터는 OKS가 지각적으로 의미있고 해석 가능한 유사성을 가질 수 있도록 튜닝하는 과정을 거칩니다.
먼저 validation 데이터 셋에서 5000개의 여분 주석을 이용하여 각 키 포인트 유형에 대해 객체 scale $s$ 에 대한 키 포인트당 표준 편차 $\sigma_i$ 를 측정했습니다. 즉 $\sigma^2=E[d_{i}^2/s^2]$ 를 계산한 것 입니다. $\sigma$ 값은 키 포인트에 따라 크게 달라집니다.
예를 들어 신체 중 몸에 있는 어깨, 무릎, 엉덩이등은 머리에 있는 눈, 코, 귀보다 훨씬 큰 $\sigma$ 를 갖는 경향이 있습니다.
지각적으로 의미있고 해석가능한 유사성 metric을 획득하기 위해서 $k_i = 2\sigma_i$ 로 설정합니다.
$k_i$ 의 설정으로 $d_i/s$ 의 표준편차 $1,2,3$ 에서 키 포인트 유사성 계산식인 $exp(-d_{i}^2/2s^2k_{i}^2)$ 는 $e^{-1/8}=0.88, e^{-4/8}=0.61, e^{-9/8}=0.32,$ 의 값을 취합니다. 따라서, 표준편차와 신뢰도의 규칙인 68-95-99.7의 규칙을 상기하면 $k_i = 2\sigma_i$ 를 설정하는 것은 사람이 레이블링한 키 포인트 주석의 $ 68%, 95%, 99.7%$ 가 각각 $0.88,0.61,0.32$ 이상의 키 포인트 유사성을 가져야 한다는 것을 의미합니다.
OKS는 모든 객체 키 포인트들의 평균 키 포인트 유사성을 의미하게 됩니다.
아래 그래프는 객체 당 10개의 독립 키 포인트(파란 곡선)을 가정하는 $k_i = 2\sigma_i$ 로 예측 OKS 분포를 그리고, 인간 OKS 점수의 실제 분포를 녹색 곡선으로 표시합니다.
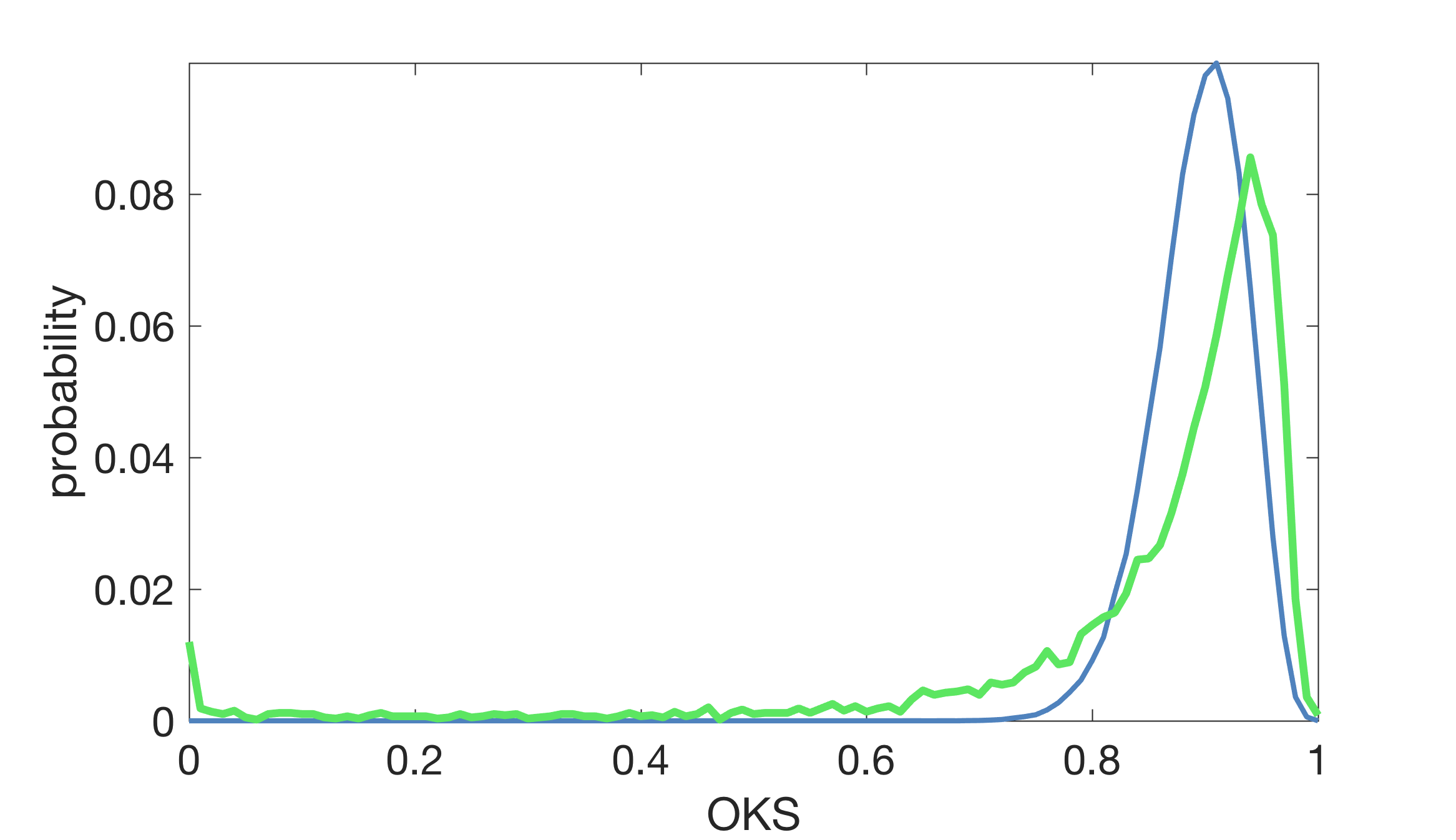
이 커브가 매칭되지 않는 몇 가지 이유는 다음과 같습니다.
- 객체 키 포인트들이 독립적이지 않습니다.
- 객체당 레이블링된 키 포인트의 수는 다양합니다.
- 실제 데이터에는 1-2%의 특이치(주석자가 왼쪽과 오른쪽 키 포인트를 오인하거나 두 사람이 근처에 있을 때 엉뚱한 사람에 주석을 달아서 발생하는 이상치)가 있어 곡선이 정확하게 일치하지 않습니다.
그렇지만 몇 가지 관찰을 통해 결론지을 수 있는 부분이 있습니다.
- OKS 0.5에서 인간의 성과는 거의 완벽합니다(95%)
- 인간의 평균 OKS는 ~0.91입니다.
- 인간의 성과는 0.95의 OKS 이후 급격히 떨어집니다.
이 OKS 분포는 인간 AR을 예측하는 데 사용될 수 있다는 점에 유의하여야 합니다. (AR는 false Positive에 의존하지 않기 때문입니다)
Metrics
다음 10개 metric들은 COCO 키 포인트 검출의 성능을 측정하는데 이용됩니다.

- AP와 AR은 복수의 OKS값(0.5:0.05:0.95)에 걸쳐 평균을 냅니다.
- 위에서 설명된 것처럼 각 키 포인트 타입 $i$ 에 대해 $k_i=2\sigma_i$ 를 설정합니다. 사람의 경우 $\sigma$ 는 각각 $0.26,0.25,0.35,0.79,0.72,0.62,1.07,0.87,0.89$로 코, 눈, 귀, 어깨, 팔꿈치, 손목, 엉덩이, 무릎, 발목입니다.
- AP(10개의 모든 OKS 임계값에 걸쳐 평균)가 COCO 키포인트 챌린지의 우승자로 결정됩니다. COCO 키포인트 성능을 고려할 때 가장 중요한 단일 지표로 간주됩니다.
- 모든 metric들은 이미지당 최대 20개의 상위 스코어 검출을 허용하는 것으로 계산됩니다.(현재 사람이 키 포인트를 가진 유일한 카테고리이기 때문에 Object Detection 챌린지처럼 100개가 아닌 20개의 검출을 사용합니다.)
- 작은 물체(세그먼트 영역<322)는 키 포인트 주석을 포함하지 않습니다.
- 군중 등 레이블링된 키 포인트가 없는 객체에 대해서는 가상의 키 포인트를 기반으로 탐지를 매칭할 수 있는 느슨한 평가를 사용합니다(자세한 사항은 코드 참조)
- 각 객체는 레이블링되거나 보이는 키 포인트들과 무관하게 동일한 중요도가 부여됩니다. 몇 개의 키 포인트만 있는 물체를 필터링하지 않고 존재하는 키 포인트 수로 객체에 가중치를 부여하지 않습니다.
키 포인트 성능 분석 코드
COCO 챌린지는 평가 코드외에 다중 인스턴스 키 포인트 추정의 오류에 대한 분석을 위해 분석 코드를 제공합니다.
코드는 아래와 같은 plot을 보여줍니다.
https://github.com/matteorr/coco-analyze
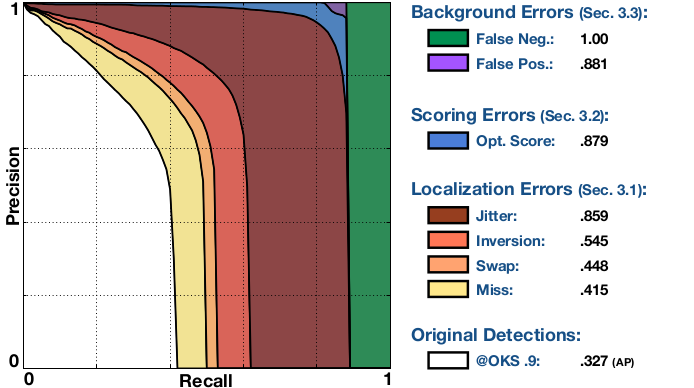
이 그림은 다중 인스턴스 포즈 추정 알고리즘의 성능에 대한 모든 유형의 오차의 영향을 요약한 그림입니다.
Precision과 Recall로 구성되며, 알고리즘의 검출이 0.9의 OKS 임계값에서 점진적으로 보정되므로 각각의 곡선이 이전보다 엄격히 높게 보장됩니다.
Original Detections : OKS=0.9에서 원래 검출로 얻은 PR, 곡선 아래 영역은 APOKS=0.9 metric에 해당합니다.
Miss : 모든 miss error를 수정한 후 OKS=0.9의 PR 값입니다. miss는 large localization error입니다 검출된 키 포인트가 적절한 신체 부분에 있지 않은 경우를 의미합니다.
Swap : 모든 swap error를 수정한 후 OKS=0.9의 PR 값입니다. swap은 이미지상의 다른 사람들의 동일한 신체 부분 사이의 혼동 때문에 일어납니다.
Inversion : 모든 inversion error를 수정한 후 OKS=0.9의 PR 값입니다. inversion은 동일한 사람 안의 신체 부분들의 혼동 때문에 일어납니다. 예를 들어 왼쪽과 오른쪽 팔꿈치등이 있습니다.
Jitter : 모든 jitter error를 수정한 후 OKS=0.9의 PR값입니다. jitter는 small localization error입니다. 검출된 키 포인트가 올바른 신체 부위와 가까운 곳에 있는 경우입니다.
Opt. Score : 모든 알고리즘의 검출이 평가 시간에 oracle function을 사용하여 재스코어링된 후 OKS=0.9의 PR 값입니다. 검출된 객체와 Ground Truth 객체 간의 일치 항목 수를 재 분류하여 최대화합니다.
FP : 모든 배경의 FP가 제거된 후 PR값입니다. FP는 최대 recall에 도달했다가 0으로 떨어질 때까지 step function입니다.(곡선은 모든 카테고리에 걸쳐 평균을 낸 후 부드러워집니다.)
FN : 나머지 오류가 모두 제거된 후 PR값 입니다(일반적으로 AP=1입니다.)
위의 키 포인트 검출기의 경우 OKS=0.9에서 전반적인 AP의 성능은 0.327입니다. 모든 miss error를 수정하면 AP가 0.415로 크게 수정됩니다. 그리고 swap의 경우 0.448, inversion의 경우 0.545로 보정할 때 더 적은 이익을 얻게 됩니다. jitter error를 수정하면 큰 개선효과를 얻어서 AUC가 0.859가 됩니다. 이 알고리즘이 키 포인트를 완벽히 localization할 겨우 어떤 성능을 발휘하는지 보여줍니다. localization 능력이 매우 우수할 때 confidence score error는의 영향은 크지 않지만, 여전히 AUC가 약 2%정도 향상됩니다. 최적으로 스코어링된 검출들은 일치하지 않는 경우가 거의 없기 때문에 배경 False Postivie에 영향을 거의 주지 않습니다. 마지막으로 배경 False negative를 제거하면 나머지 AUC가 완벽한 성능을 얻게 됩니다.
요약하면, OKS=0.9에서의 위 알고리즘의 오류는 불완전한 localization, 대부분의 jitter error, 누락된 Object Detection이 지배적입니다.
위에 주어진 코드는 총 180개의 플롯을 생성하여 3개의 영역 범위(medium, large, all)에서 10개의 임계값에서 모든 유형의 오류를 분석합니다. 분석 코드는 전체 성능 요약, 다양한 유형의 오류에 대한 method의 민감도 및 성능에 미치는 영향, 그리고 가장 중요한 실패 사례의 몇 가지 예를 포함하는 pdf 레포트를 자동으로 생성합니다.
결론
- Object Detection과 Keypoint Detection은 모두 Ground Truth 객체와 예측된 객체 사이의 유사성을 측정합니다.
- Object Detection에서는 IoU가 유사성을 측정하는 역할을 하고, IoU의 임곗값(threshold value)을 기준으로 Ground Truth 객체와 예측된 객체 사이의 매칭 여부를 판단하고 Precision-Recall Curve를 계산합니다.
- Keypoint Detection에서 Precision과 Recall을 구하기 위해서는 유사성 측정 방법이 필요한데 여기에서 Object Detection의 IoU 역할을 하는 것이 OKS(Object Keypoint Similiarity)입니다.
- 아래에 제공하는 평가 코드를 사용하여 공개된 MS COCO validation 데이터 셋 또는 MS COCO 형식을 준수한 커스텀 데이터 셋에 사용할 수 있습니다.
https://github.com/cocodataset/cocoapi